Self-supervised Taxonomy Expansion with Position-Enhanced Graph Neural Network
Motivation
Taxonomies consist of machine-interpretable semantics and support many knowledge-rich applications such as query understanding, content browsing, and personalized recommendation. Enormous efforts have been made on constructing taxonomies either manually or semi-automatically. However, as human knowledge is constantly growing, existing taxonomies will become outdated and fail to capture emerging knowledge. Therefore, in many applications, dynamic expansions of an existing taxonomy are in great demand.
Our Goal
We aim to develop an automated method that expands an existing taxonomy to incorporate a set of new concepts. Take the below figure as an example. We are given a Computer Science field-of-study taxonomy and we expand it to incorporate new concepts (e.g., UDA, Meta Learning, TPU) by finding their more appropriate parents (e.g., UDA under Semi-supervised Learning, Meta Learning under Machine Learning, and TPU under Integrated Circuit).
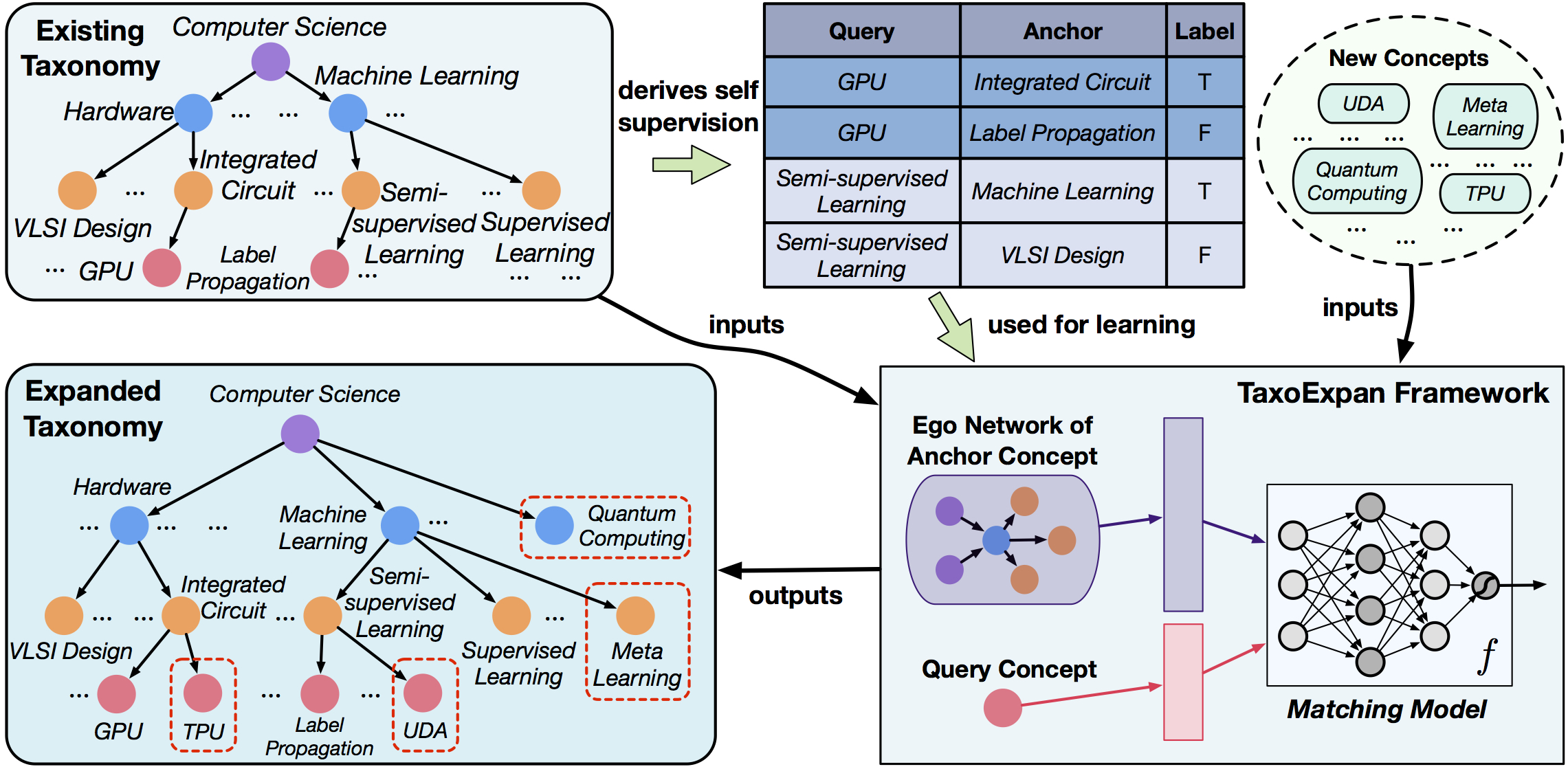
Our Approach
We propose a framework named TaxoExpan for automatic taxonomy expansion. The core of TaxoExpan is a matching model which predicts whether a “query concept” should be placed under a candidate “anchor concept” (that is, whether the “anchor concept” is the parent of “query concept”). Then, we generate “self-supervision” data from the existing taxonomy to train the matching model. Finally, at the inference stage when a new concept comes, we pair this concept with each node in the existing taxonomy, apply learned matching model on all pairs, and predict the node with the largest matching score as the query concept’s parent node.
Matching Model
Below the architecture of our matching model. Notably, we leverage the ego network (egonet) centered around the “anchor concept” to capture its neighborhood information. This egonet is then passed though a graph propagation module and a graph readout module to generate a summary vector that serves as the anchor representation. Finally, this anchor representation is combined with the query concept representation and fed into a matching module (e.g., multi-layer perceptron or log-bilinear model) to output the final matching degree.

Self-supervised Training
To train the above matching model, we generate self-supervision data from the existing taxonomy. Take the below figure as an example, we first randomly select an edge in the taxonomy (e.g., <room, gallery>) as the positive pair. Then, we construct K negative pairs by treating the child node in the selected edge (i.e., gallery) as the query and randomly selecting a set of K nodes that are neither parents nor descendants of this query. After that, we group these K+1 pairs (one positive and K negatives) into one training instance and repeat the above process to generate multiple instances. Finally, we learn the model based on InfoNCE loss using generated self-supervision data.
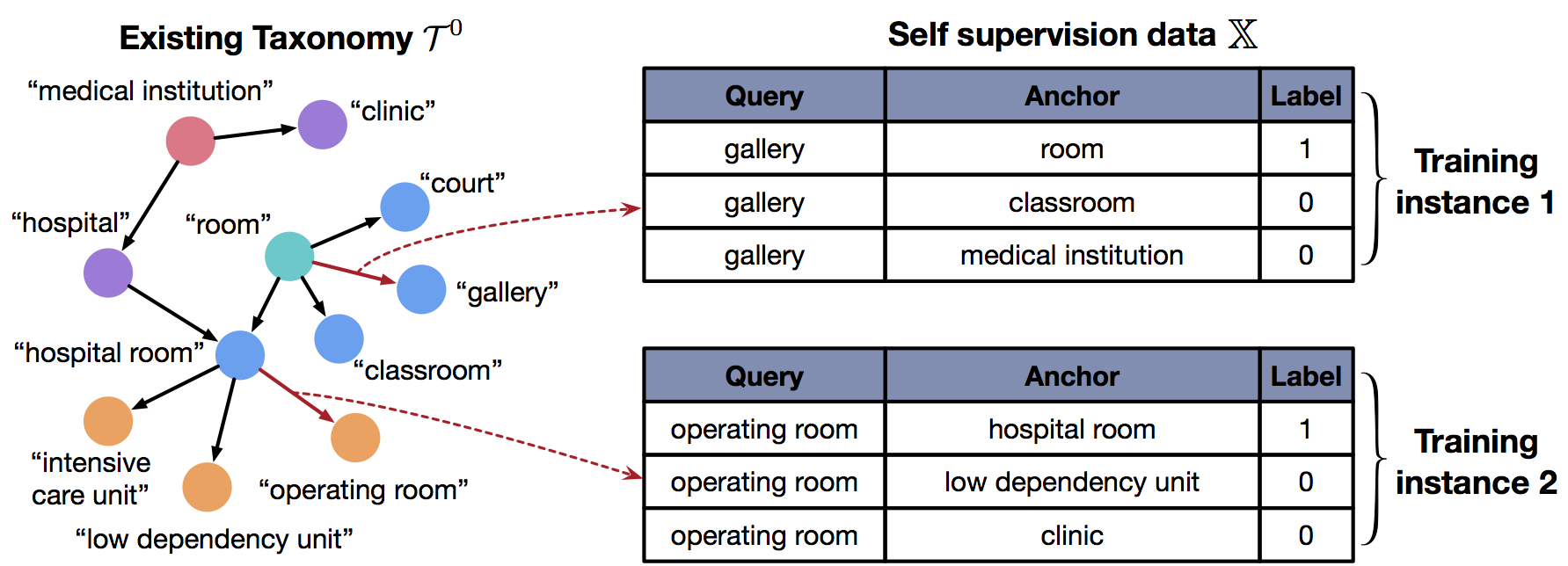
Experiments
Below is the quantitative performance comparison between TaxoExpan and related methods on Microsoft Academic Graph (MAG) dataset and SemEval 2016 Task 14 dataset.
On MAG Dataset
| Method | Mean Rank | Hit@1 | Hit@3 | Mean Recriprocal Rank |
|---|---|---|---|---|
| Closest-Parent | 1327.16 | 0.0531 | 0.0986 | 0.2691 |
| Closest-Neighbor | 382.07 | 0.1085 | 0.2000 | 0.3987 |
| dist-XGBoost | 136.86 | 0.1903 | 0.3483 | 0.6618 |
| ParentMLP | 114.79 | 0.0729 | 0.2656 | 0.6454 |
| DeepSetMLP | 115.26 | 0.1988 | 0.3581 | 0.6653 |
| TaxoExpan | 80.33 | 0.2121 | 0.3823 | 0.6929 |
On SemEval Dataset
| Method | Wu&P | Recall | F1 |
|---|---|---|---|
| MSejrKU | 0.523 | 0.973 | 0.680 |
| FWFS | 0.514 | 1.000 | 0.679 |
| ETF | 0.473 | 1.000 | 0.642 |
| ETF-FWFS | 0.563 | 1.000 | 0.720 |
| dist-XGBoost | 0.528 | 1.000 | 0.691 |
| TaxoExpan | 0.543 | 1.000 | 0.704 |
| TaxoExpan-FWFS | 0.566 | 1.000 | 0.723 |
Expanded Computer Science Taxonomy
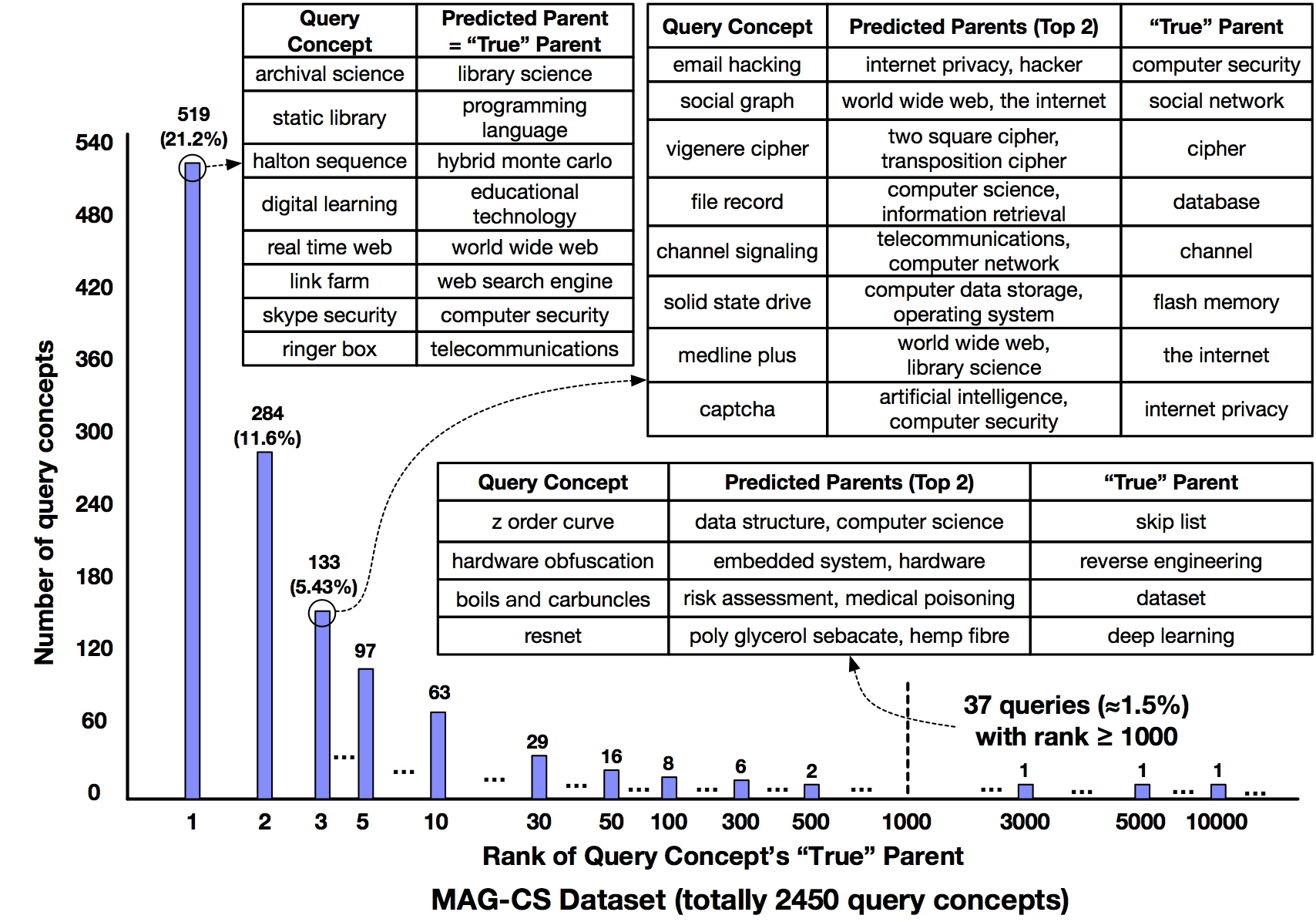
Expanded All Scienetific Fields Taxonomy

Related Materials
-
Paper Link: https://arxiv.org/abs/2001.09522
-
Code & Data: https://github.com/jmshen1994/TaxoExpan
-
Recorded WWW presentation video: https://youtu.be/5N7cWigDrDw